
The sixth problem in my list of open problems in computational diversity linguistics is devoted to the problem of simulating sound change. When formulating the problem, it is difficult to see what is actually meant, as there are two possibilities for a concrete simulation: (i) one could think of a sound system of a given language and then model how, through time, the sounds change into other sounds; or (ii) one could think of a bunch of words in the lexicon of a given language, and then simulate how these words are changed through time, based on different kinds of sound change rules. I have in mind the latter scenario.
Why simulating sound change is hard
The problem of simulating sound change is hard for four reasons. First of all, the problem is similar to the problem of sound law induction, since we have to find a simple and straightforward way to handle phonetic context (remember that sound change may often only apply to sounds that occur in a certain environment of other sounds). This is already difficult enough, but it could be handled with help of what I called multi-tiered sequence representations (List and Chacon 2015). However, there are four further problems that one would need to overcome (or at least be aware of) when trying to successfully simulate sound change.
The first of these extra problems is that of morphological change and analogy, which usually goes along with "normal" sound change, following what Anttila (1976) calls Sturtevant's paradox — namely, that regular sound change produces irregularity in language systems, while irregular analogy produces regularity in language systems. In historical linguistics, analogy serves as a cover-term for various processes in which words or word parts are rendered more similar to other words than they had been before. Classical examples are children's "regular" plurals of nouns like mouse (eg. mouses instead of mice) or "regular" past tense forms of verbs like catch (e.g., catched instead of caught). In all these cases, perceived irregularities in the grammatical system, which often go back to ancient sound change processes, are regularized on an ad-hoc basis.
One could (maybe one should), of course, start with a model that deliberately ignores processes of morphological change and analogical leveling, when drafting a first system for sound change simulation. However, one needs to be aware that it is difficult to separate morphological change from sound change, as our methods for inference require that we identify both of them properly.
The second extra problem is the question of the mechanism of sound change, where competing theories exist. Some scholars emphasize that sound change is entirely regular, spreading over the whole lexicon (or changing one key in the typewriter), while others claim that sound change may slowly spread from word to word and at times not reach all words in a given lexicon. If one wants to profit from simulation studies, one would ideally allow for a testing of both systems; but it seems difficult to model the idea of lexical diffusion (Wang 1969), given that it should depend on external parameters, like frequency of word use, which are also not very well understood.
The last problem is that of the actual tendencies of sound change, which are also by no means well understood by linguists. Initial work on sound change has been carried out (Kümmel 2008). However, the major work of finding a way to compare the major tendencies of sound change processes across a large sample of the world's languages (ie. the typology of sound change, which I plan to discuss separately in a later post), has not been carried out so far. The reason why we are missing this typology is that we lack clear-cut machine-readable accounts of annotated, aligned data. Here, scholars would provide their proto-forms for the reconstructed languages along with their proposed sound laws in a system that can in fact be tested and run (to allow to estimate also the exceptions or where those systems fail).
But having an account of the tendencies of sound change opens a fourth important problem apart from the lack of data that we could use to draw a first typology of sound change processes: since sound change tendencies are not only initiated by the general properties of speech sounds, but also by the linguistic systems in which these speech sounds are employed. While scholars occasionally mention this, there have been no real attempts to separate the two aspects in a concrete reconstruction of a particular language. The typology of sound change tendencies could thus not simply stop at listing tendencies resulting from the properties of speech sounds, but would also have to find a way to model diverging tendencies because of systemic constraints.
Traditional insights into the process of sound change
When discussing sound change, we need to distinguish mechanisms, types, and patterns. Mechanisms refer to how the process "proceeds", the types refer to the concrete manifestations of the process (like a certain, concrete change), and patterns reflect the systematic perspective of changes (i.e. their impact on the sound system of a given language, see List 2014).
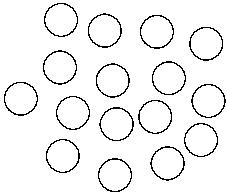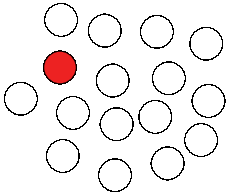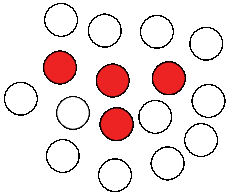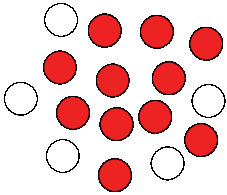 |
| Figure 1: Lexical diffusion |
The question regarding the mechanism is important, since it refers to the dispute over whether sound change is happening simultaneously for the whole lexicon of a given language — that is, whether it reflects a change in the inventory of sounds, or whether it jumps from word to word, as the defenders of lexical diffusion propose, whom I mentioned above (see also Chen 1972). While nobody would probably nowadays deny that sound change can proceed as a regular process (Labov 1981), it is less clear as to which degree the idea of lexical diffusion can be confirmed. Technically, the theory is dangerous, since it allows a high degree of freedom in the analysis, which can have a deleterious impact on the inference of cognates (Hill 2016). But this does not mean, of course, that the process itself does not exist. In these two figures, I have tried to contrast the different perspectives on the phenomena.
 |
| Figure 2: Regular sound change |
To gain a deeper understanding of the mechanisms of sound change, it seems indispensable to work more on models trying to explain how it is actuated after all. While most linguists agree that synchronic variation in our daily speech is what enables sound change in the first place, it is not entirely clear how certain new variants are fixed in a society. Interesting theories in this context have been proposed by Ohala (1989) who proposes distinct scenarios in which sound change can be initiated both by the speaker or the listener, which would in theory also yield predictable tendencies with respect to the typology of sound change.
The insights into the types and patterns of sound change are, as mentioned above, much more rudimentary, although one can say that most historical linguists have a rather good intuition with respect to what is possible and what is less likely to happen.
Computational approaches
We can find quite a few published papers devoted to the simulation of certain aspects of sound change, but so far, we do not (at least to my current knowledge) find any comprehensive account that would try to feed some 1,000 words to a computer and see how this "language'' develops — which sound laws can be observed to occur, and how they change the shape of the given language. What we find, instead, are a couple of very interesting accounts that try to deal with certain aspects of sound change.
Winter and Wedel for example test agent-based exemplar models, in order to see how systems maintain contrast despite variation in the realization (Hamann 2014: 259f gives a short overview of other recent articles). Au (2008) presents simulation studies that aim to test to which degree lexical diffusion and "regular" sound change interact in language evolution. Dediu and Moisik (2019) investigate, with the help of different models, to which degree vocal tract anatomy of speakers may have an impact on the actuation of sound change. Stevens et al. (2019) present an agent-based simulation to investigate the change of /s/ to /ʃ/ in.
This summary of literature is very eclectic, especially because I have only just started to read more about the different proposals out there. What is important for the problem of sound change simulation is that, to my knowledge, there is no approach yet ready to run the full simulation of a given lexicon for a given language, as stated above. Instead, the studies reported so far have a much more fine-grained focus, specifically concentrating on the dynamics of speaker interaction.
Initial ideas for improvement
I do not have concrete ideas for improvement, since the problem's solution depends on quite a few other problems that would need to be solved first. But to address the idea of simulating sound change, albeit only in a very simplifying account, I think it will be important to work harder on our inferences, by making transparent what so far is only implicitly stored in the heads of the many historical linguists in form of what they call their intuition.
During the past 200 years, after linguists started to apply the mysterious comparative method that they had used successfully to reconstruct Indo-European on other language families, the amount of data and number of reconstructions for the world's languages has been drastically increasing. Many different language families have now been intensively studied, and the results have been presented in etymological dictionaries, numerous books and articles on particular questions, and at times even in databases.
Unfortunately, however, we rarely find attempts of scholars to actually provide their findings in a form that would allow to check the correctness of their predictions automatically. I am thinking in very simple terms here — a scholar who proposes a reconstruction for a given language family should deliver not only the proto-forms with the reflexes in the daughter languages, but also a detailed test of how the proposed sound law by which the proto-forms change into the daughter languages produce the reflexes.
While it is clear that this could not be easily implemented in the past, it is in fact possible now, as we can see from a couple of studies where scholars have tried to compute sound change (Hartmann 2003, Pyysalo 2017, see also Sims-Williams 2018 for an overview on more literature). Although these attempts are unsatisfying, given that they do not account for cross-linguistic comparability of data (eg. they use orthographies rather than unified transcriptions, as proposed by Anderson et al. 2018), they illustrate that it should in principle be possible to use transducers and similar technologies to formally check how well the data can be explained under a certain set of assumptions.
Without cross-linguistic accounts of the diversity of sound change processes (ie. a first solution to the problem of establishing a first typology of sound change), attempts to simulate sound change will remain difficult. The only way to address this problem is to require a more rigorous coding of data (both human- and machine-readable), and an increased openness of scholars who work on the reconstruction of interesting language families, to help make their data cross-linguistically comparable.
Sign languages
When drafting this post, I promised to Guido and Justin to grasp the opportunity when talking about sound change to say a few words about the peculiarities of sound change in contrast to other types of language change. The idea was, that this would help us to somehow contribute to the mini-series on sign languages, which Guido and Justin have been initiated this month (see post number one, two, and three).
I do not think that I have completely succeeded in doing so, as what I have discussed today with respect to sound change does not really point out what makes it peculiar (if it is). But to provide a brief attempt, before I finish this post, I think that it is important to emphasize that the whole debate about regularity of sound change is, in fact, not necessarily about regularity per se, but rather about the question of where the change occurs. As the words in spoken languages are composed of a fixed number of sounds, any change to this system will have an impact on the language as a whole. Synchronic variation of the pronunciation of these sounds offers the possibility of change (for example during language acquisition); and once the pronunciation shifts in this way, all words that are affected will shift along, similar to a typewriter in which you change a key.
As far as I understand, for the time being it is not clear whether a counterpart of this process exists in sign language evolution, but if one wanted to search for such a process, one should, in my opinion, do so by investigating to what degree the signs can be considered as being composed of something similar to phonemes in historical linguistics. In my opinion, the existence of phonemes as minimal meaning-discriminating units in all human languages, including spoken and signed ones, is far from being proven. But if it should turn out that signed languages also recruit meaning-discriminating units from a limited pool of possibilities, there might be the chance of uncovering phenomena similar to regular sound change.
References
Anttila, Raimo (1976) The acceptance of sound change by linguistic structure. In: Fisiak, Jacek (ed.) Recent Developments in Historical Phonology. The Hague, Paris, New York: de Gruyter, pp. 43-56.
Au, Ching-Pong (2008) Acquisition and Evolution of Phonological Systems. Academia Sinica: Taipei.
Chen, Matthew (1972) The time dimension. Contribution toward a theory of sound change. Foundations of Language 8.4. 457-498.
Dan Dediu and Scott Moisik (2019) Pushes and pulls from below: Anatomical variation, articulation and sound change. Glossa 4.1: 1-33.
Hamann, Silke (2014) Phonological changes. In: Bowern, Claire (ed.) Routledge Handbook of Historical Linguistics. Routledge, pp. 249-263.
Hartmann, Lee (2003) Phono. Software for modeling regular historical sound change. In: Actas VIII Simposio Internacional de Comunicación Social. Southern Illinois University, pp. 606-609.
Hill, Nathan (2016): A refutation of Song’s (2014) explanation of the ‘stop coda problem’ in Old Chinese. International Journal of Chinese Linguistic 2.2. 270-281.
Kümmel, Martin Joachim (2008) Konsonantenwandel [Consonant change]. Wiesbaden: Reichert.
Labov, William (1981) Resolving the Neogrammarian Controversy. Language 57.2: 267-308.
List, Johann-Mattis (2014) Sequence Comparison in Historical Linguistics. Düsseldorf: Düsseldorf University Press.
List, Johann-Mattis and Chacon, Thiago (2015) Towards a cross-linguistic database for historical phonology? A proposal for a machine-readable modeling of phonetic context. Paper presented at the workshop "Historical Phonology and Phonological Theory [organized as part of the 48th annual meeting of the SLE]" (2015/09/04, Leiden, Societas Linguistica Europaea).
Ohala, J. J. (1989) Sound change is drawn from a pool of synchronic variation. In: Breivik, L. E. and Jahr, E. H. (eds.) Language Change: Contributions to the Study of its Causes. Berlin: Mouton de Gruyter, pp. 173-198.
Pyysalo, Jouna (2017) Proto-Indo-European Lexicon: The generative etymological dictionary of Indo-European languages. In: Proceedings of the 21st Nordic Conference of Computational Linguistics, pp. 259-262.
Sims-Williams, Patrick (2018) Mechanising historical phonology. Transactions of the Philological Society 116.3: 555-573.
Stevens, Mary and Harrington, Jonathan and Schiel, Florian (2019) Associating the origin and spread of sound change using agent-based modelling applied to /s/- retraction in English. Glossa 4.1: 1-30.
Wang, William Shi-Yuan (1969) Competing changes as a cause of residue. Language 45.1: 9-25.
Winter, Bodo and Wedel, Andrew (2016) The co-evolution of speech and the lexicon: Interaction of functional pressures, redundancy, and category variation. Topics in Cognitive Science 8: 503-513.










