
There have been a number of recent posts in the blogsphere about what is perceived to be the rather poor quality of many computer programs in bioinformatics. Basically, many bioinformaticians aren't taking seriously the need to properly engineer software, with full documentation and standard programming development and versioning.
I thought that I might draw your attention to a few of the posts here, for those of you who write code. Most of the posts have a long series of comments, which are themselves worth reading, along with the original post.
At the Byte Size Biology blog, Iddo Friedberg discusses the nature of disposable programs in research, which are written for one specific purpose and then effectively thrown away:
Can we make accountable research software?
Such programs are "not done with the purpose of being robust, or reusable, or long-lived in development and versioning repositories." I have much sympathy for this point of view, since all of my own programs are of this throw-away sort.
However, Deepak Singh, at the Business|Bytes|Genes|Molecules blog, fails to see much point to this sort of programming:
Research code
He argues that disposable code creates a "technical debt" from which the programmer will not recover.
Titus Brown, at the Living in an Ivory Basement blog, extends the discussion by considering the consequences of publishing (or not publishing) this sort of code:
Anecdotal science
He considers that failure to properly document and release computer code makes the work anecdotal bioinformatics rather than computational science. He laments the pressure to publish code that is not yet ready for prime-time, and the fact that computational work is treated as secondary to the experimental work. Having myself encountered this latter attitude from experimental biologists (the experiment gets two pages of description and the data analysis gets two lines), I entirely agree. Titus concludes with this telling comment: "I would never recommend a bioinformatics analysis position to anyone — it leads to computational science driven by biologists, which is often something we call 'bad science'." Indeed, indeed.
Back at the Business|Bytes|Genes|Molecules blog, Deepak Singh also agrees that "a lot of computational science, at least in the life sciences, is very anecdoctal and suffers from a lack of computational rigor, and there is an opaqueness that makes science difficult to reproduce":
Titus has a point
This leads to Iddo Friedberg's post (the Byte Size Biology blog) that mentions this concept:
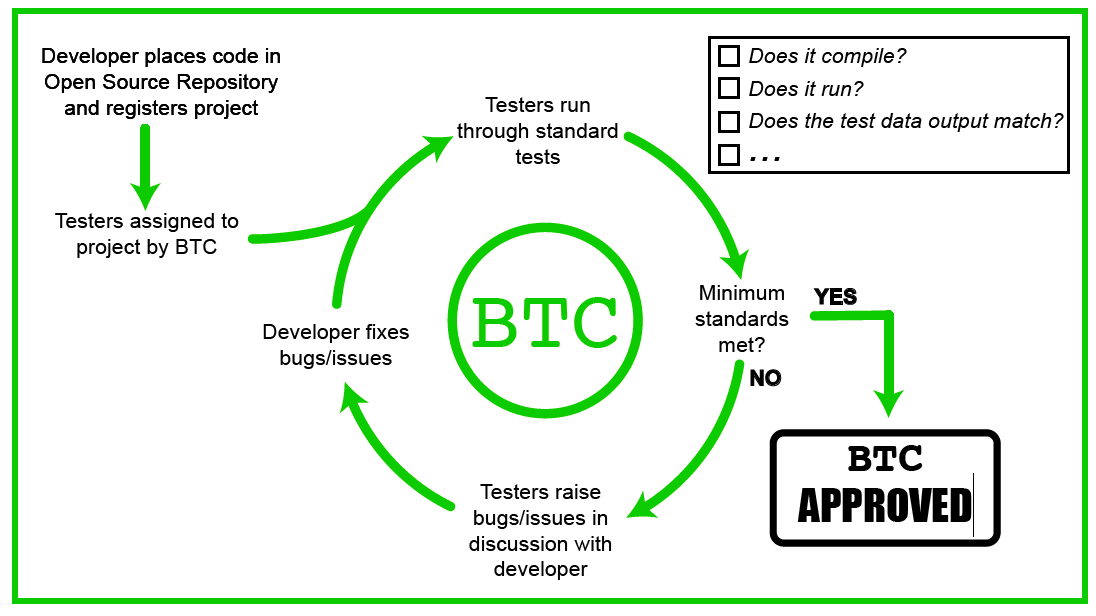
The Bioinformatics Testing Consortium
This group intends to act as testers for bioinformatics software, providing a means to validate the quality of the code. This is a good, if somewhat ambitious, idea.
Finally, Dave Lunt, at the EvoPhylo blog, takes this to the next step, by considering the direct effect on the reproducibility of scientific research:
Reproducible Research in Phylogenetics
He notes that bioinformatics workflows are often complex, using pipelines to tie together a wide range of programs. This makes the data analysis difficult to reproduce if it needs to be done manually. Hence, he champions "pipelines, workflows and/or script-based automation", with the code made available as part of the Methods section of publications.
This is a subject that has bugged me (no pun intended) for a very long time. I think the majority of programming done in bioinformatics is of the disposable kind and that does not lend itself to much validation or verification at all. Further, most bioinformatics software is doing complicated things, frequently with some (pseudo)random element too. It's therefore really hard to test. And then, most bioinformatics software is not written by programmers per se: they (we!) are often self taught or have at least come into software development secondarily after a background in mathematics, statistics, or molecular biology. Programs are in large part written to answer a particular question, not to be used by the multitude.
ReplyDeleteOn the other hand, there is this pressure to publish rapidly, which means a slowing-down of the process by developing a testing framework is not acceptable: I've told students NOT to worry about perfect code (in terms of maintainability, modularity) because they won't get on to answering the research question in the one semester they have otherwise. I do get them to test their code as well as possible but other niceties go by the wayside because we don't have time.
A couple of years ago I worked with a group on metamorphic testing, not my own concept but it's a good one, and which we applied to a couple of
programs in the PHYLIP package. We were really pleased to find that the tests we subjected the code to were rigorous and that the programs were very robust and correct. Really excellent code. We also tested code by applying simple mutations to it: i's changed to j's, <'s changed to >'s, that kind of thing. Errors that programmer might make and that might go unnoticed because the code still compiles. That too showed how solid the two tested programs were against our meddling. So it's possible to do such things but it does take lots of time.
I don't know if there's a long term solution other than leading by example. Changing a culture is hard but possible. While we might not always be in a position to create perfect software for every task, longer-term software can be improved.