
I have written before about the distinction between phylogenetic networks and other types of biological network (see Biological versus phylogenetic networks). Basically, a phylogenetic network starts with observed data and infers the network connections via some optimization procedure, whereas for most other networks the connections are the observed data and the network is summarized by one or more statistics such as Degree Centrality or Betweenness Centrality (for an explanation, see Network measures and phylogenetic networks).
This distinction is also important for the use of networks as data displays, both in biology and elsewhere. I have noted that splits networks, for example, are a very useful alternative to multivariate data-display analyses such as Principal Components Analysis (see Networks can outperform PCA ordinations in phylogenetic analysis). PCA can, for example, produce mathematical artifacts that distort the display, which is obviously undesirable (see Distortions and artifacts in Principal Components Analysis analysis of genome data).
It is interesting, therefore, to compare the different network types in terms of their ability to analyze and display a particular data set. To demonstrate the generality of the methods, here I discuss an analysis of a text document.
The one I have chosen has previously been analyzed by Seth Long (Text Network and Corpus Analysis of the Unabomber Manifesto). The Unabomber Manifesto is a 35,000 word document from 1995 entitled "Industrial Society and its Future", written by Theodore (Ted) Kaczynski, which is basically a critique of contemporary techno-capitalist society. A textual analysis is of interest because, as Seth notes: "The motives of all authors — or at least their traces — are always left behind in the lexical choices of their texts. Deliberate, written language is like a rhetorical fingerprint."
Textual analyses
Seth Long's textual analysis procedure was:
- import the text into an analytical tool (in this case AutoMap) in order to remove trivial words (eg. articles, conjunctions, pronouns), and to reduce inflected words to their base form;
- use the same tool to quantify what words are connected to what other words and how often (in this case using a two-word gap);
- import the result into a a network analysis tool (in this case Gephi) in order to visualize the semantic connections; each word is visualized as a node in the network, and words that appear next to each other appear as edges in the network.
The two most important network visualizations, in my opinion, show nodes with the highest levels of Betweenness Centrality and the highest levels of Degree Centrality. The latter measures how many total connections a node has to other individual nodes. The former measures whether or not a node is connected to other nodes that themselves have many connections.
In a textual network, a word with high degree centrality is a word used in connection with a myriad of other words. This simply tells you that a word is used frequently in a text and in a variety of contexts. A word with high betweenness centrality is a word used frequently and in conjunction with other words that also connect to other nodes to form community clusters. This tells you that a word is not only used frequently and not only in many contexts but also that it is used in connection with words that also do a lot of semantic work in the text. A word with high betweenness centrality is a word through which many meanings in a text circulate.
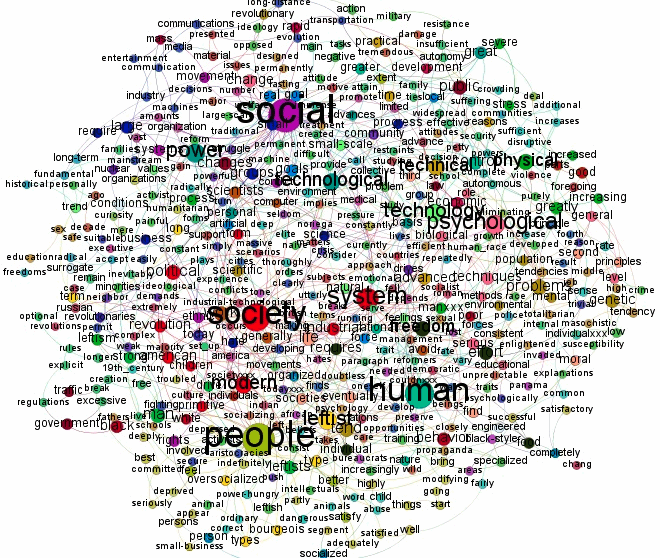 |
| Nodes with the greatest Degree Centrality in the text |
 |
| Nodes with the greatest Betweenness Centrality in the text |
The size of the words in the two networks represents their "amount" of centrality (ie. their importance). Clearly, these networks are very complex, and it would be best to simplify them. Seth does this in some of his other textual analyses, where he uses "one of Gephi’s degree range tools to hide the most disconnected nodes, thereby ‘cleaning’ the visualization of all but the most prominent clusters and connections" (eg. see Meaning circulation in Lolita). This has not been done in this example.
I will not provide an interpretation of these two networks, which you can find in Seth's original post. The basic conclusion is that "Kaczynski is a primitivist who loves nature more than humanity."
Seth also notes:
One thing a text network does, beyond providing an interesting visualization, is to point the researcher in the direction of terms and n-grams that might be explored more granularly in a corpus analysis tool, such as the NLTK [Natural Language Toolkit]. It provides a map of a text’s semantic circulation, a map that can be followed when we return to the world of pure textuality.The two corpus analyses that Seth Long provides are a histogram of the most frequent words, and a graph of where in the text the most frequent words fall (beginning, middle, end, throughout, etc).
Phylogenetic analyses
We can now compare these analyses to the use of phylogenetic trees and networks as heuristic tools for data analysis and display. The objective is the same as for the above analyses, and the general approach is also very similar. The main difference, as explained above, is that the nodes and edges are inferred rather than observed. This means that the words appear only at the ends of terminal edges, rather than being scattered throughout the network.
These analyses involve:
- remove trivial words, count the frequency of the remaining words, simplify the network by choosing how many of the words to display (50 in this case), and record their location in the text;
- calculate the semantic "distance" between words based on their co-occurrence in a sliding window (in this case 20 words), using some similarity measure (in this case the jaccard coefficient);
- visualize the distances as an unrooted phylogenetic tree, in this case a neighbor-joining tree calculated using TreeCloud;
- visualize the distances as an unrooted phylogenetic network, in this case a neighbor-net (a splits graph) calculated using SplitsNetworkCloud.
 |
| TreeCloud of the text |
 |
| NetworkCloud of the text |
In these phylogenetic analyses, the size of the words represents their frequency in the text, and the colour of the words represents their location in the text (red near the beginning, blue near the end). This adds the corpus analyses to the network visualization, making the graphs more informative. This can happen because the visualization itself is the inferred network, rather than the visualization summarizing various aspects of centrality of the underlying observed network.
The relative distance between two words in the text is given by the relative length of the path between them in the tree or network. Note that the "clean-up" of the graphs, by restricting the number of included words, helps a lot with the interpretation (as it would if also applied to the previous two graphs).
The phylogenetic tree focuses on certain of the word connections, rather than trying to display them all — it tries to infer which connections are "important" based on the measure of semantic distance, rather then connecting all nearby words. The interpretations from the tree are similar to those from the previous networks, but in many ways the interpretations are displayed more directly by the inferred (phylogenetic) graph than by summarizing centrality (either degree or betweenness).
Finally, the network is much more complex than the tree, which is often the case. Note that for the tree the edge lengths are all equal, but in the network the "average" distance between two words is given by the length of the path between them. This is just for illustrative purposes, as the tree could be drawn with variable edge lengths or the network drawn with unit edge lengths. The main reason for using unit edge lengths is that the terminal edges are often very long and the structure of the tree or network is hidden in the centre, as discussed by Gambette et al. (2012).
The main patterns that the network adds to the tree are: (a) "human" is separately associated with "control" and "behavior" on one hand and "beings" on the other; (b) "power" is separately associated with "process" and "autonomy" on one hand and "satisfy" on the other; and (c) "primitive" is separately associated with "individuals", "societies" and "groups" on one hand and "modern" and "man" on the other.
Conclusion
The phylogenetic approach is helpful because it focuses on certain of the network connections, rather than trying to display them all, as do the other networks. It cannot separately analyze concepts like degree and betweenness, and so information is lost; but this is traded off against the ability to include corpus analyses such as word frequency and location. Phylogenetic trees and networks can thus be valuable tools for textual analysis.
The TreeCloud was introduced by Gambette and Véronis (2010). If you read French, then examples are presented by Amstutz and Gambette (2010) and by Gambette and Martinez (2012) (the latter has a comparison with some other multivariate data anlayses).
Thanks to Philippe Gambette for producing the NetworkCloud.
References
Amstutz D., Gambette P. (2010) Utilisation de la visualisation en nuage arboré pour l'analyse littéraire. JADT'10: 10th International Conference on Statistical Analysis of Textual Data.
Gambette P., Gala N., Nasr A. (2012) Longueur de branches et arbres de mots. Corpus 11: 129-146.
Gambette P., Martinez W. (2012) L'affaire du Mediator au prisme de la textométrie. Manuscript.
Gambette P., Véronis J. (2010) Visualising a text with a tree cloud. In: Locarek-Junge H., Weihs C. (eds) Classification as a Tool of Research, Proceedings of IFCS'09 (11th Conference of the International Federation of Classification Societies), pp. 561-570.
No comments:
Post a Comment